- 1. What splitBy and flatten does?
-
splitBy is use to Splits a string into a string array. Performs the opposite operation as Join By.splitBy can be used TWO ways
-
splitBy(String, Regex): Array(String)
- It Splits a string into a string array based on a value that matches part of that string.
- It accepts a Java regular expression (regex) to match the input string.
- The regex can match any character in the input string.
Example :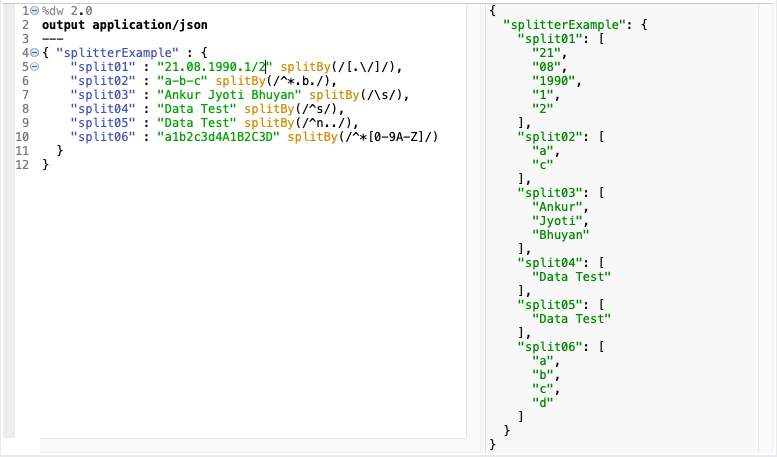
-
splitBy(String, String): Array(String)
- It Splits a string into a string array based on a separating string that matches part of the input string.
- The separator can match any character in the input.
Example :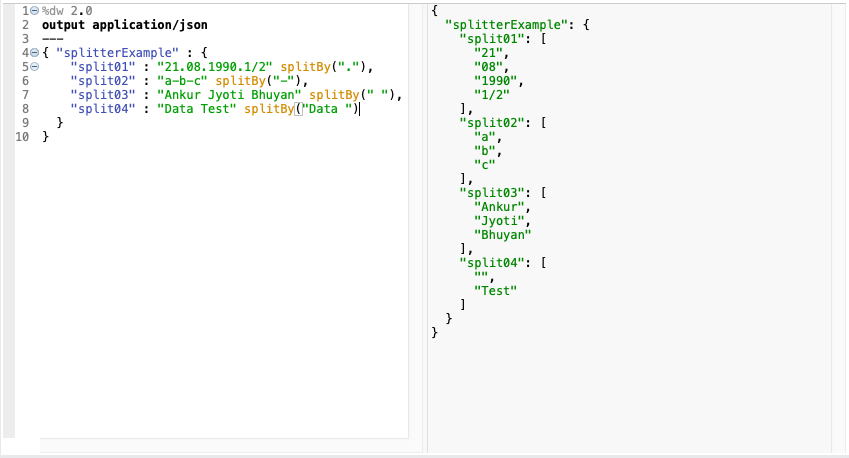
-
splitBy(String, Regex): Array(String)
-
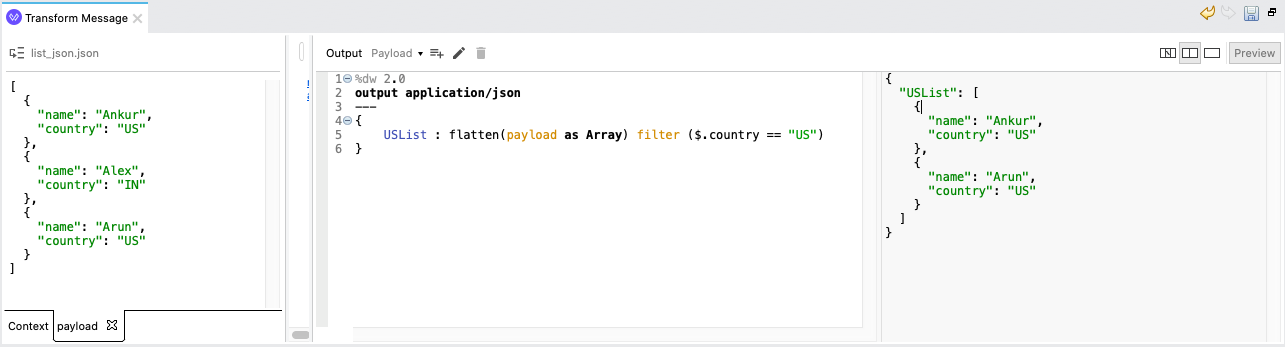
flatten is use to convert an array of arrays.
-
(':array') ⇒ ':array'
- Turns a set of subarrays (such as [ [1,2,3], [4,5,[6]], [], [null] ]) into a single, flattened array (such as [ 1, 2, 3, 4, 5, [6], null ]).
Example :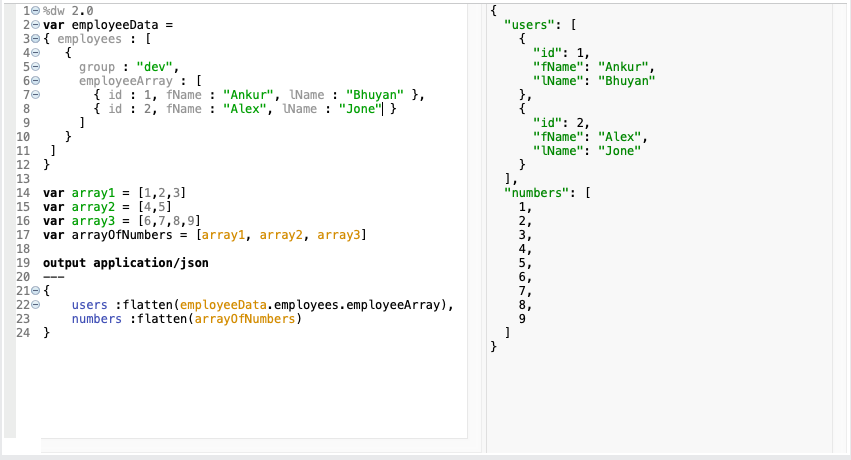
-
(':array') ⇒ ':array'
- 2. Difference between map and mapObject in DW?
-
map
- Returns : (':array', ':function') ⇒ :array
-
Syntax : map(Array
, (item: T, index: Number) -> R): Array(R) -
Parameters :
- items -> The array to map.
- mapper -> Expression or selector used to act on each item and optionally, each index of that item.
- Iterates over items in an array and outputs the results into a new array.
-
mapObject
- Returns : (':object', ':function') ⇒ ':array'
- Syntax : mapObject({ (K)?: V }, (value: V, key: K, index: Number) -> Object): Object
-
Parameters :
- object -> The object to map.
- mapper -> Expression or selector that provides the key, value, or index used for mapping the specified object into an output object.
- Iterates over an object using a mapper that acts on keys, values, or indices of that object.
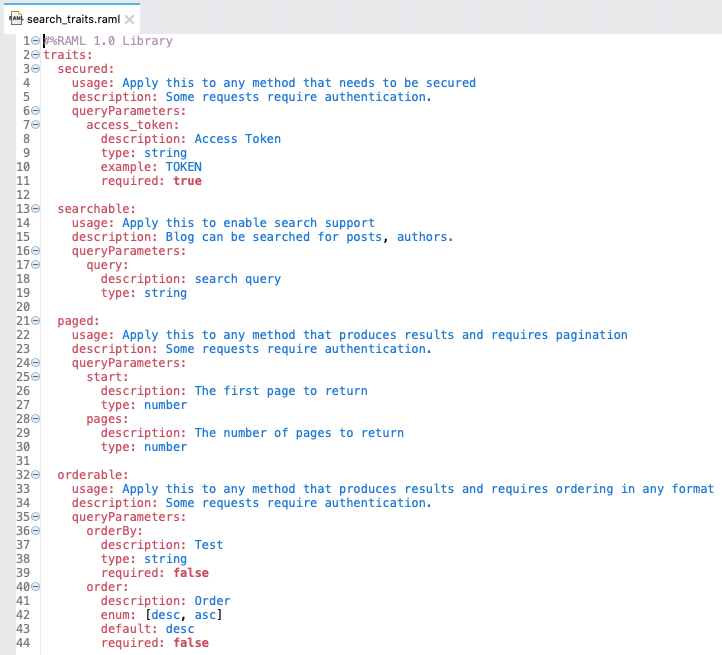
- 3. What is traits?
Traits is like function and is used to define common attributes for HTTP method (GET, PUT, POST, PATCH, DELETE, etc) such as whether or not they are filterable, searchable, or pageable.
- 8. What is Auto Discovery?
API Autodiscovery is a mechanism that manages an API from API Manager by pairing the deployed application to an API created on the platform.
API Management includes tracking, enforcing policies if you apply any, and reporting API analytics. Critical to the Autodiscovery process is identifying the API by providing the API name and version.
- 9. How to resolve outOfMemory Error in Mule application & in Java Application?
-
IN Anypoint Studio -> FOR MULE
- You can modify the maximum heap size so it suits your project's needs, in order to do so you'd need to go to:
- Run -> Run Configurations... -> Select the Mule Application. And in VM Arguments, increase the value for XX:MaxPermSize to increase the Perm Size or add the -Xmx param to increase the Heap, i.e: -Xmx1024M.
-
IN Eclipse -> FOR JAVA
- Right mouse click on : Run As - Run Configuration - Arguments - Vm Arguments, then add this : -Xmx2048m
The configuration can be modified in the servers /conf/wrapper.conf file
# Limit the Metaspace Size to protect system memory from unwanted usage
# Increase this value if you get "Java.lang.OutOfMemoryError: Metaspace" error
wrapper.java.additional.7=-XX:MetaspaceSize=128m
wrapper.java.additional.8=-XX:MaxMetaspaceSize=256m
# Increase this value if you get "Java.lang.OutOfMemoryError: Metaspace" error
wrapper.java.additional.7=-XX:MetaspaceSize=128m
wrapper.java.additional.8=-XX:MaxMetaspaceSize=256m
- 10. What is proxy?
API proxies, also known as "autogenerated proxies", are meant to enhance the usability of API Manager in your Mule application.
Typical usage: Either when we want to leverage API Gateway capabilities and our backend API is not based on Mule Runtime, or when our API is based on Mule Runtime but you are unable to define the corresponding Autodiscovery element because it is a closed code.
- 11. How to change HTTP Listener to DEBUG log in LOCAL and CLOUD environment?
-
In LOCAL: Please use the following configuration in your custom log4j2.xml file:
<AsyncLogger name="org.mule.service.http.impl.service.HttpMessageLogger" level="DEBUG"/> -
In CLOUD: You need to add the following configuration to the Settings page of the application in the LOGGING tab:
DEBUG org.mule.module.http.internal.HttpMessageLogger
- 12. What is API Runtime and API Manager?
-
API Manager
- API manager is there to create and configure APIs but Rumtime will host application i.e. nothing but Cloudhub having Mule runtime.
- In API Manager 2.x, we can use instances of an API in multiple environments, and we can have multiple instances in the same environment.
- Through the Autodiscovery scheme, API Manager can track the API throughout the life cycle as you modify, version, deploy, govern, and publish it.
-
API Manager 2.x is tightly integrated with the following tools:
- Design Center for creating the RAML structure of the API :- The API design capabilities of Design Center replace the Jul 2017 API Designer tool in Anypoint Platform.
- Exchange for storing and publishing API assets :- Assets are components, such as API versions, templates, and connectors owned by MuleSoft or your organization.
- Studio for implementing the API :- API changes made in Studio are synchronized using Autodiscovery with the API registered in other tools, such as Design Center and API Manager.
-
Runtime Manager
-
The Runtime Manager REST API enables us to programmatically access these functions of Runtime Manager:
-
Manage servers:
- Register a server.
- Get a list of registered servers.
- Get information about a server.
- Change the server name.
- Shut down, restart, or delete a server.
- Renew server certificates.
- Get a server registration token.
-
Manage server groups:
- Create a server group from a list of servers.
- Get a list of registered server groups.
- Get information about a server group.
- Change the server group name.
- Add or remove a server from a server group.
- Delete a server group.
-
Manage clusters:
- Create a cluster.
- Get a list of registered clusters.
- Get information about a cluster.
- Change the cluster name.
- Add or remove a server from a cluster.
- Modify clustering information for a server.
- Delete a cluster.
-
Manage app deployments on your servers:
- Deploy, redeploy, and undeploy apps.
- Get application deployment and status information.
- Manage flows, schedulers, and alerts in a deployed app.
-
Manage servers:
-
The Runtime Manager REST API enables us to programmatically access these functions of Runtime Manager:
- 13. What is scalable? How to define vertical and horizontal scaling?
- Vertical scale or scale-up: Adding more compute or memory resources for your applications increases the maximum capacity of the server. When demand spikes, there should not be any noticeable change to your applications.
- Horizontal scale or scale-out: Adding more individual servers into a resource pool where your applications run.
- Diagonal scaling: Essentially a combination of vertical and horizontal scaling, this setup will scale vertically first until you reach a preset limit and then scale the system horizontally.
From a business point-of-view, scalability is the ability to serve customers seamlessly even when a sudden change in demand occurs.
From an IT point-of-view, scalability is the ability to add/remove infrastructure resources needed by business applications to manage the increased/decreased demand in the number of business transactions.
There are three types of scalability options:
- 14. Difference between Rate Limit and Throttling in Mulesoft?
-
Rate Limiting:
- The Rate Limiting policy limits the number of requests an API accepts within a window of time.
- The API rejects requests that exceed the limit. You can configure multiple limits with window sizes ranging from milliseconds to years.
-
Throttling:
- The Throttling policy queues requests that exceed limits for possible processing in a subsequent window.
- The API eventually rejects the request if processing cannot occur after a certain number of attempts. You can configure a delay between retries, as well as limit the number of retries.
-
Rate Limiting (SLA-Based):
- The Rate Limiting policies based on a service level access (SLA) are client ID-based policies that use the client ID as a reference to impose limits on the number of requests that each application can make within a period of time.
- To use these policies you need to create at least one SLA tier to define request limits.
The Rate Limiting and Throttling policies impose a limit on all requests or a specific resource (in Mule 3.x and earlier, the API must be APIkit-based).
The service level access (SLA)-based Rate Limiting and Throttling policies add further granularity, limiting requests by the level of access granted to the requesting application.
Rate Limiting and Throttling policies are designed to limit API access, but have different intentions: Rate limiting protects an API by applying a hard limit on its access. Throttling shapes API access by smoothing spikes in traffic.
- 15. What is object store and why we use them?
- in-memory store :- Mule persists data by default.
- persistent store :- Mule persists data when an object store is explicitly configured to be persistent. Mule creates a default persistent store in the file system.
-
Contains:
- Checks whether the object store contains the given key.
<objectstore:contains key="MUL0001" config-ref="config-name"/> - Return boolean :- true if the object store contains the key, or false if it doesn't.
-
Dual Store:
- Stores a value using key and also stores a key using value. If an exception is thrown rolls back both operations. This allows an option to indicate if key would be overwritten or not.
<objectstore:dual-store key="MUL0001" value-ref="#[string:Ankur Bhuyan]" config-ref="config-name"/> - Return boolean :- true if you want to overwrite the existing object.
-
Remove:
- Remove the object for the respective key. This operation can fail silently based on the value passed in ignoreNotExists.
<objectstore:remove key="MUL0001" config-ref="config-name"/> - Return Serializable :- The object that was previously stored for the given key. If the key does not exist and ignoreNotExists is true the operation will return a null object.
-
Retrieve:
- Retrieve an object from the object store and make it available in the specified property scope of a Mule Message.
<objectstore:retrieve key="MUL0001" defaultValue-ref="#[string:Ankur Bhuyan]" config-ref="config-name"/> - Return Serializable :- The object associated with the given key. If no object for the given key was found this method throws an ObjectDoesNotExistException.
-
Retrieve All Keys:
- Returns a list of all the keys in the object store.
<objectstore:retrieve-all-keys> - Return List(String) :- a java.util.List with all the keys in the store.
-
Retrieve And Store:
- Retrieve and Store in the same operation.
<objectstore:retrieve-and-store> - Return Serializable :- The object associated with the given key. If no object for the given key was found this method returns the defaultValue.
-
Store:
- Stores an object in the object store. This allows an option to indicate if key would be overwritten or not.
<objectstore:store key="MUL0001" value-ref="#[string:Ankur Bhuyan]" config-ref="config-name"/> - Return boolean :- True if you want to overwrite the existing object.
An object store is a facility for storing objects in Mule. Mule uses object stores whenever it needs data to persist for later retrieval. Internally, Mule uses object stores in various filters, routers, and other message processors that need store their state between messages. In most cases, Mule creates and manages object stores automatically, so no user configuration is necessary.
Mule provides two types of object stores for non-clustered servers:
Namespace -> xmlns:objectstore="http://www.mulesoft.org/schema/mule/objectstore"
Dependency Details ->
<dependency>
<groupId>org.mule.modules</groupId>
<artifactId>mule-module-objectstore</artifactId>
<version>2.0.0</version>
</dependency>
The Object Store connector is an operation-based connector : Contains, Dual Store, Remove, Retrieve, Retrieve All Keys, Retrieve And Store, Store.
- 16. What is DDL and DML?
-
Stands for:
- DDL : DDL stands for Data Definition Language.
- DML : DML stands for Data Manipulation Language.
-
Usage:
- DDL : DDL statements are used to create database, schema, constraints, users, tables etc.
- DML : DML statement is used to insert, update or delete the records.
-
Classification:
- DDL : DDL has no further classification.
- DML : DML is further classified into procedural DML and non-procedural DML.
-
Commands:
- DDL : CREATE, DROP, RENAME and ALTER.
- DML : INSERT, UPDATE and DELETE.
- 17. What is $ and $$ means in DataWeave?
The $ symbol can be used for accessing the VALUE of a key-value pair in a map.
$$ can be used for getting the KEY (or index) of the key-value pair.
- 18. How to configure HTTPS connection?
- This connector provides Secure HTTP connectivity on top of what is already provided with the Mule HTTP Transport.
- Secure connections are made on behalf of an entity, which can be anonymous or identified by a certificate.
- The key store provides the certificates and associated private keys necessary for identifying the entity making the connection.
- Additionally, connections are made to trusted systems.
- The public certificates of trusted systems are stored in a trust store, which is used to verify that the connection made to a remote system matches the expected identity.
-
In order to setup a HTTPS server with Mule a few first steps need to be performed. First a keystore must be created, this can be done using the keytool provided by Java. You can find this in the bin directory of the Java installation.
Once located you can then execute the following command to create a keystore: keytool -genkey -alias mule -keyalg RSA -keystore keystore.jks -
This will create a file in the local directory called keystore.jks
Ideally this should be created in the MULE_HOME/conf directory if to be used across multiple applications or can be put into theMY_MULE_APP/src/main/resourcesdirectory if being used within a single application. -
If the keystore was in the
MY_MULE_APP/src/main/resourcesdirectory then you can just specify the name in the path.
Otherwise if the keystore was located in theMULE_HOME/confdirectory then you will have to specify"${mule.home}/conf/keystore.jks"as the path. -
Configuration Reference :
-
tls-client :
Configures the client key store with the following attributes:- path: The location (which will be resolved relative to the current classpath and file system, if possible) of the keystore that contains public certificates and private keys for identification
- storePassword: The password used to protect the keystore
- class: The type of keystore used (a Java class name)
-
tls-key-store :
Configures the direct key store with the following attributes:- path: The location (which will be resolved relative to the current classpath and file system, if possible) of the keystore that contains public certificates and private keys for identification
- class: The type of keystore used (a Java class name)
- keyPassword: The password used to protect the private key
- storePassword: The password used to protect the keystore
- algorithm: The algorithm used by the keystore
- keyAlias: The alias of the key to use
-
tls-server :
Configures the trust store. The attributes are:- path: The location (which will be resolved relative to the current classpath and file system, if possible) of the trust store that contains public certificates of trusted servers
- class: The type of trust store used (a Java class name)
- storePassword: The password used to protect the trust store
- algorithm: The algorithm used by the trust store
- factory-ref: Reference to the trust manager factory
- explicitOnly: Whether this is an explicit trust store
- requireClientAuthentication: Whether client authentication is required
- tls-protocol-handler : Configures the global Java protocol handler. It has one attribute, property, which specifies the java.protocol.handler.pkgs system property.
-
tls-client :
Example : <https:connector name="httpConnector">
<https:tls-client path="clientKeystore" storePassword="mulepassword"/>
<https:tls-key-store path="serverKeystore" storePassword="mulepassword" keyPassword="mulepassword"/>
<https:tls-server path="trustStore" storePassword="mulepassword"/>
</https:connector>
<https:endpoint name="clientEndpoint" host="localhost" port="60202" connector-ref="httpConnector" />
- 19. How to call an another API in Mulesoft?
Using HTTP Requester
- 20. What is Regression and BlackBox Testing?
-
REGRESSION TESTING :
- REGRESSION TESTING is defined as a type of software testing to confirm that a recent program or code change has not adversely affected existing features.
- Regression Testing is nothing but a full or partial selection of already executed test cases which are re-executed to ensure existing functionalities work fine.
- This testing is done to make sure that new code changes should not have side effects on the existing functionalities. It ensures that the old code still works once the latest code changes are done.
-
BLACK BOX TESTING :
- BLACK BOX TESTING, also known as Behavioral Testing, is a software testing method in which the internal structure/design/implementation of the item being tested is not known to the tester. These tests can be functional or non-functional, though usually functional.
-
This method attempts to find errors in the following categories:
- Incorrect or missing functions
- Interface errors
- Errors in data structures or external database access
- Behavior or performance errors
- Initialization and termination errors
-
Types of Black Box Testing : There are many types of Black Box Testing but the following are the prominent ones -
- Functional testing - This black box testing type is related to the functional requirements of a system; it is done by software testers.
- Non-functional testing - This type of black box testing is not related to testing of specific functionality, but non-functional requirements such as performance, scalability, usability.
- Regression testing - Regression Testing is done after code fixes, upgrades or any other system maintenance to check the new code has not affected the existing code.
-
Tools used for Black Box Testing : Tools used for Black box testing largely depends on the type of black box testing you are doing -
- For Functional/ Regression Tests you can use - QTP, Selenium
- For Non-Functional Tests, you can use - LoadRunner, Jmeter
- 21. What is Router, Modem and Switch?
-
Modem
- Stands for "modulating-demodulating".
- A modem is often provided by your ISP (Internet Service Provider) which enables a network access to the internet.
- Modems are hardware devices that allow a computer or another device, such as a router or switch, to connect to the Internet. They convert or "modulate" an analog signal from a telephone or cable wire to digital data (1s and 0s) that a computer can recognize.
- Simply send traffic from point A to piont B without further manipulation.
-
Routers
- Are responsible for sending data from one network to another.
- When connecting more than one device to a modem, a router is generally required. A router acts as the “traffic director” of a network.
- Work at Layer 3 (Network) of the OSI model, which deals with IP addresses.
- Typically, routers today will perform the functionality of both a router and a switch - that is, the router will have multiple ethernet ports that devices can plug into.
-
Switches
- They use the MAC address of a device to send data only to the port the destination device is plugged into.
- Work at Layer 2 (Data Link) of the OSI model, which deals with MAC addresses.
- A switch (such as a 10GbE switch or Gigabit PoE switch) is used to provide additional ports, expanding the capability of the router.
- 22. Difference between ResourceTypes and Traits?
-
What Is ResourceTypes?
- ResourceTypes is like resource in that it can specify the descriptions, methods, and its parameters. Resource that uses resourceTypes can inherit its nodes. ResourceTypes can use and inherit from other resourceTypes.
- In order to implement the patterns found in the API, resource types use reserved and user-defined parameters surrounded by double angle brackets (<< and >>).
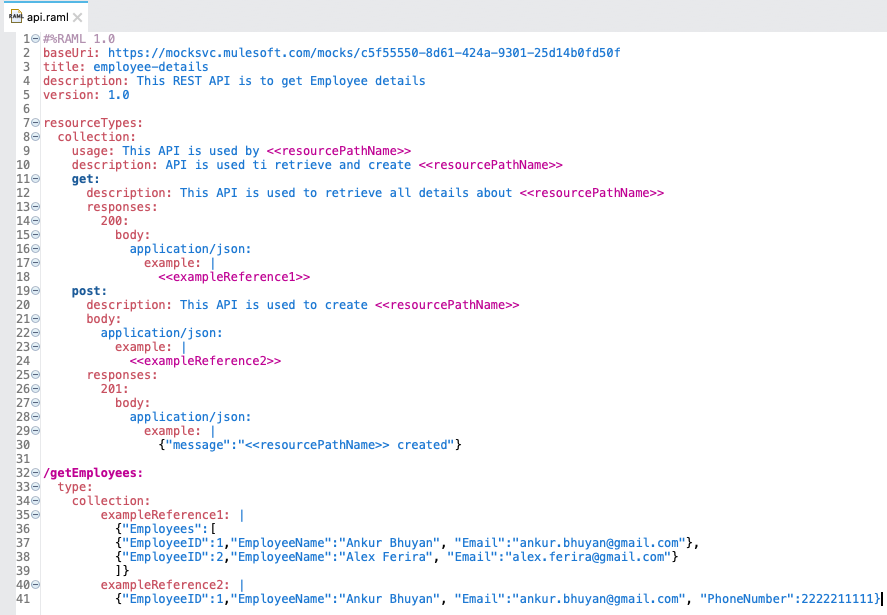
-
What Is Traits?
- Traits is like function and is used to define common attributes for HTTP method (GET, PUT, POST, PATCH, DELETE, etc) such as whether or not they are filterable, searchable, or pageable.
- Whereas a resource type is used to extract patterns from resource definitions, a trait is used to extract patterns from method definitions that are common across resources.
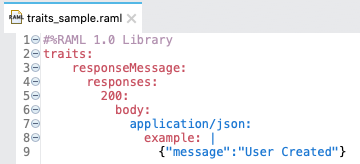
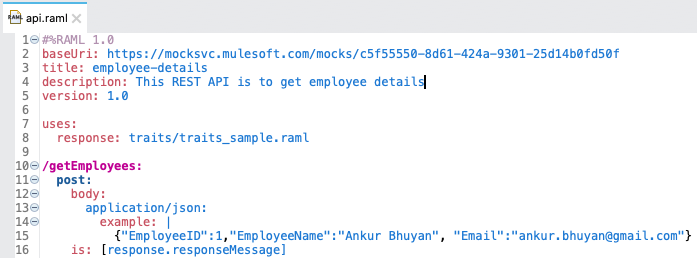
- 23. What map, mapObject and flatten returns?
-
map :
- It returns ARRAY.
-
Syntax :
- map(Array < T >, (item: T, index: Number) -> R): Array < R >
- map(Null, (item: Nothing, index: Nothing) -> Any): Null
-
mapObject :
- It returns Object.
-
Syntax :
- mapObject({ (K)?: V }, (value: V, key: K, index: Number) -> Object): Object
- mapObject(Null, (value: Nothing, key: Nothing, index: Nothing) -> Any): Null
-
flatten :
- It returns ARRAY.
-
Syntax :
- flatten(Array< Array < T > | Q>): Array < T | Q >
- flatten(Null): Null
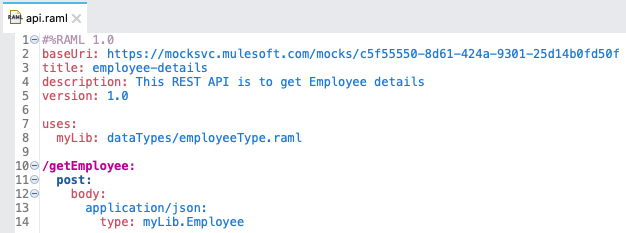
- 24. Under which component we will define the dataTypes in RAML?
Any data Types in RAML is define under types: section.
Example:
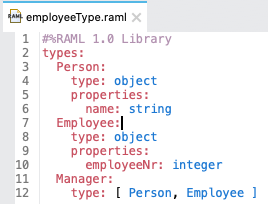
- 25. How to define multiple security patterns in single resource?
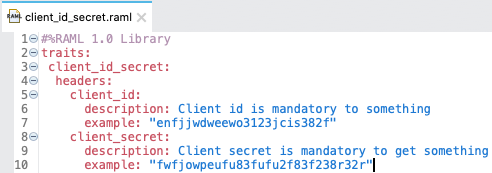
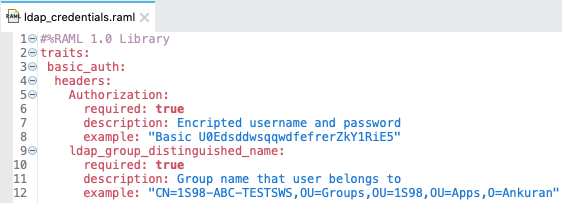
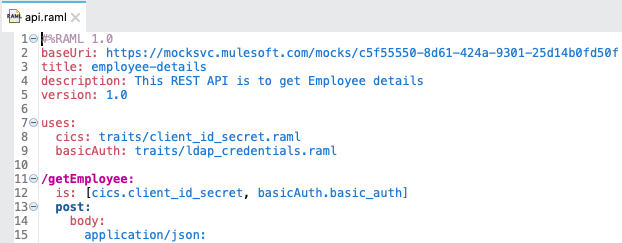
We can define number of security patterns under is section using Square brackets "[]" separated by comma.
Example:
- 26. What are the Thread pools available for MuleSoft?
- CPU_LITE
- CPU_INTENSIVE
- BLOCKING_IO
- GRIZZLY(Shared) - Custom
- GRIZZLY(Dedicated) - Custom
By default these THREE pools available in Mulesoft containers.
Apart from these THREE pools we have TWO custom containers.
- 28. How to define secured properties in property file and how to access in Flow and DataWeave?
- Define secured properties in property file : encrypted.value=![s/wzDQR6xdpOCwddas3wdsdhNBAp7VR8NAgBKmwQA=]
- Access secured properties in DataWeave : p(‘secure::encrypted.value’)
- Access secured properties in flow : "${secure::encrypted.value}"
Comments