- 1. How to secure resources in raml?
-
With securitySchemes
securitySchemes: customClientSecurity: !include security-scheme/customClientSecurityScheme.raml securedBy: - customClientSecurity -
With traits
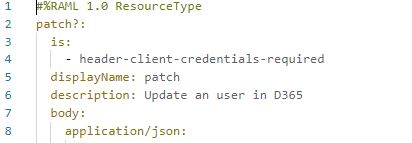
- 2. How to restrict the unwanted request payload using raml?
To accept only the properties defined, the attribute additionalProperties: false must be set (by default is true).
properties:
my-object:
type: object
additionalProperties: false
properties:
id:
type: string
required: true
maxLength: 161
- 3. What is fragements? What are the fragments available in RAML?
- API fragments are reusable components that you can create and publish to be utilized in various APIs in your business organization.
- We can have fragments within your API specification to increase the flexibility of your API specification.
- Available fragments in RAML are,
- Resource types.
- Common traits.
- Securities fragment.
- Domain fragment.
- 4. What is the Syntax to import a "common library", "traits", "dataTypes" and "resourceTypes" in raml?
uses:
warning-lib: /exchange_modules/98b6d1c2-304e-408c-8732-feffa0df17c0/ana-common-warn/1.0.0/ana-common-warn.raml
traits:
header-access-token-required: !include /exchange_modules/98b6d1c2-304e-408c-8732-feffa0df17c0/1.0.0/header-access-token-required.raml
types:
credential: !include /common/dataTypes/credential.raml
resourceTypes:
create-order: !include /orders/create-order/resourceType.raml
- 5. What is a library and how to define it?
RAML libraries are pre-defined sets of Data Types, Resource Types, Traits, Security Schemes, and reusable assets.
One of the main advantages of Libraries is modularization and they can enable reusability.
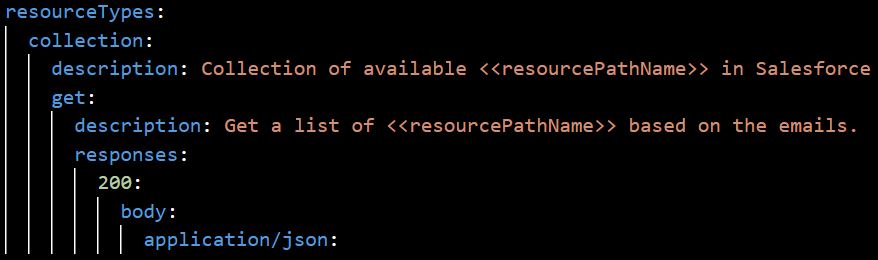
- 6. What are the two reserve keys to define resourceType?
<<resourcePath>> represents the entire URI. <<resourcePathName>> repesents the part of URI following the righmost forward slash (/).
A Reserved Parameter simply is a parameter with a value automatically specified by its context.
- 8. What is SecuritySchemas? What is the use of it? Difference between SecurityScheme and Trait?
- Security schemes is used in RAML to define what kind of security enabled for the API.
- It can be basic auth, clientId and secret, OAUth 2.0.
- SecuritySchemas is an optional element in the RAML root.
- SecuritySchemas contains the definition of the security that would be used to secure the api and it its method.
-
Difference between SecurityScheme and Trait
- Security schemes are specialised RAML fragments design to support the definition of a range of security types.
- The scheme provides a set of keys typically required for proper security configuration.
- A trait is a generic RAML fragment that can be used to define almost any part of an API specification design.
- They promote modular design and can be used to define secured endpoints when the security schema does not suffice.
- In short, always use security scheme for defining secure endpoints and traits for everything else.
- To apply the security schema you will use secureBy command and for traits you will use is command in the resources.
Example 1 : Client ID enforcement
#%RAML 1.0 SecurityScheme
type: x-client-id-and-secret-custom
description: Client ID and Secret Based Security
describedBy:
headers:
client_id:
description: Client Id in base 64 format
client_secret:
description: Client Secret in base 64 format
responses:
401:
description: "Unauthorized."
securitySchemes:
customClientSecurity: !include security-scheme/customClientSecurityScheme.raml
securedBy:
- customClientSecurity
Example 2 : OAuth enforcement
#%RAML 1.0 SecurityScheme
type: x-custom-oAuth
description: OAuth Based Security
describedBy:
headers:
Authorization:
description: Token to validate the client APP
responses:
401:
description: "Unauthorized."
securitySchemes:
customOAuthSecurity: !include security-scheme/customOAuthSecurityScheme.raml
securedBy:
- customOAuthSecurity
- 9. On what scenarios RAML minor, majaor or patch version get updated? If we added a new resource, will client get impact? And what would be the version we are going update (minor or major)?
-
Major versions
- MAJOR version increment indicates incompatible API changes.
- When introducing a change in the structure of the API that requires the user of the API to adapt the interface on the consumer side, such as a new required operation argument.
-
Minor versions
- MINOR version increment indicates addition of functionality in a backwards-compatible manner.
- When introducing a backward compatible change to the API that does not require an API user to change, such as a new optional element.
-
Patch versions
- PATCH version increment indicates backwards-compatible bug fixes.
- When introducing a backward compatible bug fix or documentation update.
- 10. How to make a asynchronous flow to synchronous?
- Use the "maxConcurrency" property in Mule 4 instead maxActiveThreads in Mule 3.9
- When a producer component outputs information at a higher rate than a consumer component can process it, you can use the maxConcurrency parameter to set the maximum number of concurrent messages that a flow can process at any given time, whether the components are internal or external, flows or sources, and so on.
- Under heavy load, Mule runtime engine (Mule) might not immediately have the resources available to process a specific event.
- This issue might occur because all threads are busy and the current flow’s concurrency is exceeded.
- When this occurs, Mule logs the following message: Flow 'flowName' is unable to accept new events at this time
- When a producer component outputs information at a higher rate than a consumer component can process it, you can use the maxConcurrency parameter to set the maximum number of concurrent messages that a flow can process at any given time, whether the components are internal or external, flows or sources, and so on.
-
Flow scope
- Sets the maximum number of concurrent messages that a flow can process. If not set, the container thread pool determines the maximum number of threads the flow can use to optimize the performance when processing messages.
- While the flow is processing the maximum number of concurrent messages, it cannot receive additional requests.
- Set maxConcurrency to 1 to cause the flow to process requests one at a time.
- Mule 4 decouples thread configuration from concurrency management. To control concurrency on a flow or any component that supports it, use the maxConcurrency attribute to set the number of simultaneous invocations that component can receive an any given time.
<flow name="perf-test-flow" maxConcurrency="${flow.max.concurrency}"> -
Scatter-Gather router
- Determines the maximum amount of concurrent routes to process.
- By default all routes run in parallel.
- By setting this value to 1, scatter-gather processes the routes sequentially.
<scatter-gather name="Scatter-Gather" maxConcurrency="${scatter.max.concurrency}"/> -
Async scope
- Sets the maximum number of concurrent messages that the scope can process.
- By default, the container thread pool determines the maximum number of threads to use to optimize the performance when processing messages.
- When the scope is processing the maximum number of concurrent messages, it cannot receive additional requests.
- Set maxConcurrency to 1 to cause the scope to process requests one at a time.
<async name="Async" maxConcurrency="${async.max.concurrency}"/> -
Batch Job scope
- The maximum number of threads used for processing within a Batch scope defaults to 2 times the number of cores that the JVM detects.
- On fractional core deployments, such as CloudHub and Anypoint Runtime Fabric, the JVM detects a non-fractional number of cores. You can manually increase or lower the automated concurrency setting.
- The Max Concurrency setting enables you to set an upper limit on the number of threads to use for a batch job instance that, for example, has insufficient records to warrant more threads.
<batch:job jobName="test-batch" maxConcurrency="${batch.max.concurrency}"> -
Parallel For Each scope
- "maxConcurrency" specifies the maximum level of parallelism for the router to use. By default, all routes run in parallel.
- For Parallel Foreach, By default (when no maxConcurrency provided), all routes run in parallel. And for Batch Job it is twice the number of available cores.
- "maxConcurrency" decides how many threads can execute parallelly at the same time, Let's say if it is set to 2 and total records to be processed are 10 then remaining 8 will be queued.
-
"maxConcurrency" is also affected by the capability/capacity of the system also. Meaning, if you are not providing the value for maxConcurrency parameter does not mean it will for sure
- Execute all routes at once (Parallel Foreach)
- Take 2 x available cores (Batch Job)
<parallel-foreach jobName="test-parallel-foreach" maxConcurrency="${parallel.max.concurrency}">
Using "maxConcurrency"
Back-Pressure
The following components provide a max concurrency setting:
- 11. Difference between foreach and parrallel-foreach? Difference between scatter-gather and parrallel-foreach?
-
"For Each" works sequentially, while the "Parallel For Each" processes in parallel. This difference affects error handling
- Because of the processing differences, the execution of "For Each" execution is interrupted when an error is raised (and the Error Handler is invoked), while "Parallel For Each" processes every route before invoking the Error Handler with a MULE:COMPOSITE_ROUTE error type.
- "For Each" does not modify the payload, while the "Parallel For Each" outputs a collection of the output messages from each iteration.
- Both "For Each" and "Parallel For Each" split the defined collection, and the components within the scope process each element in the collection. Also, in both cases, each route runs with the same initial context.
- "Parallel For-Each" iterates through a collection of elements n times (where n is less than or equal to the number of elements in the collection) with a single process. For example, if there are 10 elements and the maximum number of processes is set to 2, a Parallel For-Each processes two elements at a time. total iteration would be 5 times
- "Scatter-gather" runs two or more parallel processes, called routes. When all the routes are finished, the results from each route are gathered into a new payload.
Difference between "For each" and "parrallel-foreach":
Difference between "scatter-gather" and "parrallel-foreach" :
- 12. What is TLS? What is Trust Store and Key Store? Difference between one way and two TLS configuration? How the handshake will happen?
- TLS is a cryptographic protocol that provides end-to-end security of data sent between applications over the Internet.
- "Trust Store" store certificates from Certified Authorities (CA).
- "Key Store" store private key and identity certificates.
- "Trust Store" holds onto certificates that identify others.
- "Key Store" typically holds onto certificates that identify us.
-
For servers (HTTP Listener):
- The truststore contains certificates of the trusted clients.
- The keystore contains the private and public key of the server.
-
For clients (HTTP Requestor):
- The truststore contains certificates of the trusted servers.
- The keystore contains the private and public key of the client.
- "Key store" is used to store private key and identity certificates that a specific program should present to both parties (server or client) for verification.
- "Trust store" is used to store certificates from Certified Authorities (CA) that verify the certificate presented by the server in an SSL connection.
- One way TLS: In one way TLS the client always verifies the server certificates but server never verifies the client certificates.
- Two way TLS: In Two way TLS client and server authenticate or exchange the certificates with each other.
- Steps for configuring One way TLS
-
Generate server keystore:
keytool -genkey -alias mule-server -keyalg RSA -keystore C:\certs\server-keystore.jks -
Extract public key from Keystore:
keytool -export -alias mule-server -keyalg RSA -keystore C:\certs\server-keystore.jks -file C:\certs\server_trust.crt. -
Create trust store for client:
keytool -import -alias mule-server -keyalg RSA -keystore C:\certs\client-truststore.jks -file C:\certs\server_trust.crt
-
Generate server keystore:
- Steps for configuring Two way TLS
-
Generate server keystore:
keytool -genkey -alias mule-server -keyalg RSA -keystore C:\certs\server-keystore.jks -
Extract public key from Keystore:
keytool -export -alias mule-server -keyalg RSA -keystore C:\certs\server-keystore.jks -file C:\certs\server_trust.crt. -
Create trust store for client:
keytool -import -alias mule-server -keyalg RSA -keystore C:\certs\client-truststore.jks -file C:\certs\server_trust.crt -
Generate client keystore:
keytool -genkey -alias mule-server -keyalg RSA -keystore C:\certs\client-keystore.jks -
Extract public key from client Keystore:
keytool -export -alias mule-server -keyalg RSA -keystore C:\certs\client-keystore.jks -file C:\certs\client_trust.crt -
Create trust store for server:
keytool -import -alias mule-server -keyalg RSA -keystore C:\certs\server-truststore.jks -file C:\certs\client_trust.crt
-
Generate server keystore:
- 13. What is shared resource?
- When we deploy Mule on premises, we can define global configurations such as default error handlers, shared properties, scheduler pools, and connector configurations to be shared among all applications deployed under the same domain.
-
Sharing resources allows multiple development teams to work in parallel using the same set of connector configurations, enabling the teams to:
- Expose multiple services within the domain through the same port.
- Share the connection to persistent storage.
- Share services between Mule applications through a well-defined interface.
- Ensure consistency between Mule applications upon any changes because the configuration is only set in one place.
- 14. Difference between Shared and Load balancer?
-
Shared Load Balancer :
Provides basic load balancing functionality.
- A shared load balancer in CloudHub resides outside the client's VPC.
- It's a shared resource, shared between customers and common for a specific CloudHub region.
- SLB is used for load balance external APIs.
- SLB supports HTTPS protocol but the user can not add it's custom certificates, sub-domains and can't expose custom vanity domain names.
-
Dedicated Load Balancer :
Enables you to deploy and configure one or more custom load balancers within an Anypoint Virtual Private Cloud (Anypoint VPC).
- A dedicated load balancer is not shared resource in CloudHub and resides inside the client's VPC, user can configure more than one DLB in VPC.
- As a part of a client's VPC users can configure and customize it.
- Users can assign n number of workers for high availability, upload custom certificates, upload client certificate, configure custom vanity domain, IP whitelist/blacklist and configure sub-domains.
- As DLB is not a shared resource in CloudHub, So users can write custom URL mapping rules and run multiple API endpoints under the same domain name.
- 15. What are the design patterns you worked on?
- Messaging patterns
-
-
Advantage of having Messaging pattern
- Loosely coupled
- Asynchronous – Receiver will get the message as soon as it arrives on the AMQ. Receiver don’t have to check the AMQ on regular intervals
- Reliable – AMQ ensure/guarantee the delivery of messages and that to only once.
-
Patterns :
-
Publish/subscribe
- The publish/subscribe pattern is where an application publishes messages (publisher) and any number of other services will receive them (subscribers).
- Applications that are interested in a publisher’s messages “subscribe” to a predefined channel that they know publishers will be sending messages to.
- Use this pattern when multiple things need to happen for each event. For instance, when a user performs an action (submits a form), and you need to update several databases, send notifications, update other APIs, etc.
- This pattern also allows you to add new functionality without interrupting or changing existing code. New applications can simply subscribe to the channel to receive the messages and perform new functions.
-
Message queue
- The message queue pattern is very common and is, essentially, what message queues were built for.
- Producers push messages into a queue and consumers take those messages off the queue.
- Only one consumer gets a particular message, no matter how many consumers are asking for messages from that queue.
-
Many-to-one
- When you must be sure that only one consumer can get the messages on a particular channel, this is the pattern you’ll use.
- This isn’t a very common pattern as there are few use cases for it, but the main one would be if a particular consumer must store state between messages, or if messages must be processed in exactly the right order.
-
Request/Response
- Send a message, receive a response. Sounds a lot like a synchronous system such as a REST API and you wouldn’t be wrong for thinking that.
- The general idea is that the publisher includes a destination for a consumer to publish another message with the reply/response.
-
Publish/subscribe
-
Advantage of having Messaging pattern
- Integration patterns
-
-
Migration
- Migration is the act of moving data from one system to the other.
- Data migration is moving a specific set of data at a particular point in time from one system to another.
- A migration pattern allows developers to build automated migration services that create functionality to be shared across numerous teams in an organization.
-
Broadcast
- The broadcast Salesforce integration pattern moves data from a single source system to multiple destination systems in an ongoing, near real-time, or real-time basis.
- Essentially, it is one-way synchronization from one to many. Typically “one way sync” implies a 1:1 relationship; the broadcast pattern creates a 1:many relationship.
- In contrast to the migration pattern, the broadcast pattern is transactional and is optimized for processing records as quickly as possible. Broadcast patterns keep data up-to-date between multiple systems across time.
-
Bi-directional sync
- This type of integration comes in handy when different tools or different systems, which are needed for their own specific purposes, must accomplish different functions in the same data set.
- Using bi-directional sync enables both systems to be used and maintains a consistent real-time view of the data across systems.
- Bi-directional sync integration enables the systems to perform optimally while maintaining data integrity across both synchronized systems.
-
Aggregation
- Aggregation removes the need to run multiple migrations on a regular basis, removing concerns about data accuracy and synchronization.
- It is the simplest way to extract and process data from multiple systems into a single application or report.
- By using an Salesforce integration template built on an aggregation pattern, it’s possible to query multiple systems on demand and merge data sets to create or store reports in .csv or other formats of choice, for example. Aggregation contains a custom logic that can be modified to merge and format data as needed and which can be easily extended to insert data into multiple systems, such as Salesforce, SAP and Siebel.
-
Correlation
- The correlation pattern singles out the intersection of two data sets and does a bi-directional synchronization of that scoped dataset, but only if that item occurs in both systems naturally.
- Bi-directional synchronization will create new records if they are found in one system and not the other. The correlation pattern does not discern the data object’s origin. It will agnostically synchronize objects as long as they are found in both systems.
-
Migration
- Reliability Design Pattern
-
- High-reliability applications must have zero tolerance for message loss. This means that both the underlying Mule and its individual connections need to be reliable.
- If your application uses a transactional connection such as JMS, VM, or DB, reliable messaging is ensured by the built-in support for transactions in the connector.
- This means, for example, that you can configure a transaction on a JMS listener that makes sure messages are removed only from the JMS server when the transaction is committed. Doing this ensures that if an error occurs while processing the message, it is still available for reprocessing.
- In other words, the transactional support in these connectors ensures that messages are delivered reliably from a source to an operation, or between processors within a flow.
- Non-Transactional transport like HTTP, File and SFTP doesn’t support transaction. Request received on such Transport can end up in message loss as if anything goes wrong within mule flow. To make such interaction more reliable this pattern can be used with connector which supports Transaction e.g. VM, JMS and DB. This will guarantee there is zero loss of messages and all request are process with at most reliability.
- 16. What is Circuit Breaker?
- Circuit breaker is a design pattern used in software development. It is used to detect failures and encapsulates the logic of preventing a failure from constantly recurring, during maintenance, temporary external system failure or unexpected system difficulties.
- The Circuit Breaker design pattern is used to stop the request and response process if a service is not working, as the name suggests.
- States of Circuit Breaker Pattern
-
Circuit Breaker Pattern consist of THREE states : Closed, Open, and Half Open.
-
Closed State :
- The initial state of the circuit breaker or the proxy is the Closed state.
- The circuit breaker allows microservices to communicate as usual and monitor the number of failures occurring within the defined time period.
- If the failure count exceeds the specified threshold value, the circuit breaker will move to the Open state. If not, it will reset the failure count and timeout period.
-
Open State :
- Once the circuit breaker moves to the Open state, it will completely block the communication between microservices.
- So, the service will not receive any requests, and the user service will receive an error from the circuit breaker.
- The circuit breaker will remain in the Open state until the timeout period ends. Then, it will move into the Half-Open state.
- Half-Open State :
- In the Half-Open state, the circuit breaker will allow a limited number of requests to reach service.
- If those requests are successful, the circuit breaker will switch the state to Closed and allow normal operations. If not, it will again block the requests for the defined timeout period.
- The circuit breaker will remain in the Open state until the timeout period ends. Then, it will move into the Half-Open state.
-
Closed State :
-
Closed State to Open State:
- Transition Trigger : Request failed with threshold limit.
- Description : When the monitored metrics breach the predefined thresholds while the Circuit Breaker is in the Closed state, indicating potential issues with the downstream service, it transitions to the Open state. This means that the Circuit Breaker stops forwarding requests to the failing service(that is experiencing issues or failures)and provides fallback responses to callers.
-
Half-Open State to Closed State:
- Transition Trigger: Request successful with threshold value.
- Description : After a specified timeout period in the Open state, the Circuit Breaker transitions to the Half-Open state. In the Half-Open state, a limited number of trial requests are allowed to pass through to the downstream service. If these trial requests are successful and the service appears to have recovered, the Circuit Breaker transitions back to the Closed state, allowing normal traffic to resume.
-
Half-Open State to Open State:
- Transition Trigger: Request failed.
- Description : While in the Half-Open state, if the trial requests to the downstream service fail, indicating that the service is still experiencing issues, the Circuit Breaker transitions back to the Open state. This means that requests will again be blocked, and fallback responses will be provided until the service’s health improves.
-
Open State to Half-Open State:
- Transition Trigger: Counter reset timeout.
- Description : After a specified timeout period in the Open state, the Circuit Breaker transitions to the Half-Open state. This timeout period allows the Circuit Breaker to periodically reevaluate the health of the downstream service and determine if it has recovered.
-
Circuit Breaker Pattern consist of THREE states : Closed, Open, and Half Open.
- Circuit Breaker Capability with Anypoint MQ
- The Subscriber source provides circuit breaking capability, which enables us to control how the connector handles errors that occur while processing a consumed message.
- When connecting to an external service, we can use the circuit breaker to handle any downtime of that service. The circuit breaker allows the system to stop making requests and allows the external service to recover under a reduced load.
- When the external service is not available, every attempt to process a message results in a failure, forcing the app to loop, consuming messages that cannot succeed. You can avoid this behavior by notifying the subscriber of the error in a way that prevents it from consuming more messages for a certain period.
-
Circuit Breaker Processes :
- The circuit breaker capability that the Subscriber source provides is bound to the error handling mechanism provided by Mule. It uses the error notification mechanism to count errors related to an external service, which is known as a circuit failure.
- We can bind any error to a circuit failure. For example, we can bind HTTP:TIMEOUT, FTP:SERVICE_NOT_AVAILABLE, or even a custom error from your app, such as ORG:EXTERNAL_ERROR.
- When errorsThreshold is reached, the circuit trips and remains open for the duration specified by tripTimeout. While the circuit is open, all polled or consumed messages are not acknowledged (NACK) and Anypoint MQ halts any future operations (poll, ACK, NACK, and Publish) until tripTimeout elapses.
- After tripTimeout elapses, the circuit breaker transitions to a new state. If the new state is Closed, clients can consume messages on the next poll.
-
The behavior varies depending on whether we deploy the app to CloudHub with a single worker or multiple workers:
- Single worker : The worker processes messages individually from the queue and opens the circuit breaker when the number of errors reaches the value of errorsThreshold.
- Multiple workers : Each worker has an associated circuit breaker and tracks the values of errorsThreshold and tripTimeout individually. Each worker processes messages individually from the queue and opens the circuit breaker when the number of errors reaches the value of errorsThreshold set on the worker.
-
Configure Circuit Breaker : We can configure a Circuit Breaker as either a Global Circuit Breaker or a Private Circuit Breaker :
- onErrorTypes : The error types that count as a failure during the flow execution. An error occurrence counts only when the flow finishes with an error propagation. By default, all errors count as a circuit failure.
- errorsThreshold : The number of onErrorTypes errors that must occur for the circuit breaker to open.
- tripTimeout : How long the circuit remains open once errorsThreshold is reached.
- circuitName : The name of a circuit breaker to bind to this configuration. By default, each queue has its own circuit breaker.
- Advantages of Circuit Breaker Pattern
- Helps to prevent cascading failures.
- Handles errors gracefully and provides better under experience.
- Reduces the application downtimes.
- Suitable for handling asynchronous communications.
- State changes of the circuit breaker can be used for error monitoring.
- Implement Custom Policy in API Manager: Circuit Breaker Policy
- 17. What is Saga Pattern?
- The SAGA pattern is a design pattern used in distributed systems and microservices architecture to manage and coordinate long-running transactions or processes that involve multiple services.
- It provides a structured way to ensure data consistency and reliability in a distributed environment, where transactions may span multiple services or databases.
- The SAGA pattern offers a way to manage distributed transactions without relying on a traditional two-phase commit (2PC) protocol, which can be complex and has limitations in distributed systems.
- Instead, it embraces the idea of eventual consistency and uses compensation actions to handle failures and maintain data integrity.
-
SAGA is implemented in two ways:
- SAGA as Choreography
- SAGA as Orchestration
- Follow more for examples : Example 1, Example 2.
- 18. What is the difference between RTF and hybrid models?
- Hybrid is a combination of CloudHub and On-premise, which provides features and benefits of both.
- RTF is a container service that allows customers to perform multiple-cloud deployments of Mule runtimes.
-
Hybrid :
- Run mule applications on your own Mule Servers by deploying and managing through Runtime Manager.
- Mule Applications could be run on servers hosted on premise / data center or in Cloud.
- Each Server has to be registered with Runtime Manager and then organized into Server Group or Clusters for high availability.
-
RTF :
- RTF is a container based service that provides iPaaS based environment for all customer managed infrastructure whether it be Bare metal Servers / VMs or AWS or Azure.
- RTF comes with all components required for running Mule Services on a container based environment such as Docker and Kubernetes.
- 19. The API getting un responsive many times in a day. How to fixed it?
- In Runtime Manager, click Applications in the menu on the left.
- Click Deploy Application and select CloudHub from Deployment Target.
- Select the "Automatically restart application when not responding" option.
- 20. How to create connection pool for DB connection?
- 21. What is the full form SSO? Difference between Id Token and Access Token?
- Full form of SSO is : Single Sign On
-
They can both be encoded as JWT, but the content and purpose are also different.
- An ID token contains the identity information about the authenticated users, and it is intended to be consumed by the front-end application.
- On the other hand, an access token represents a ticket with permission to consume an API.
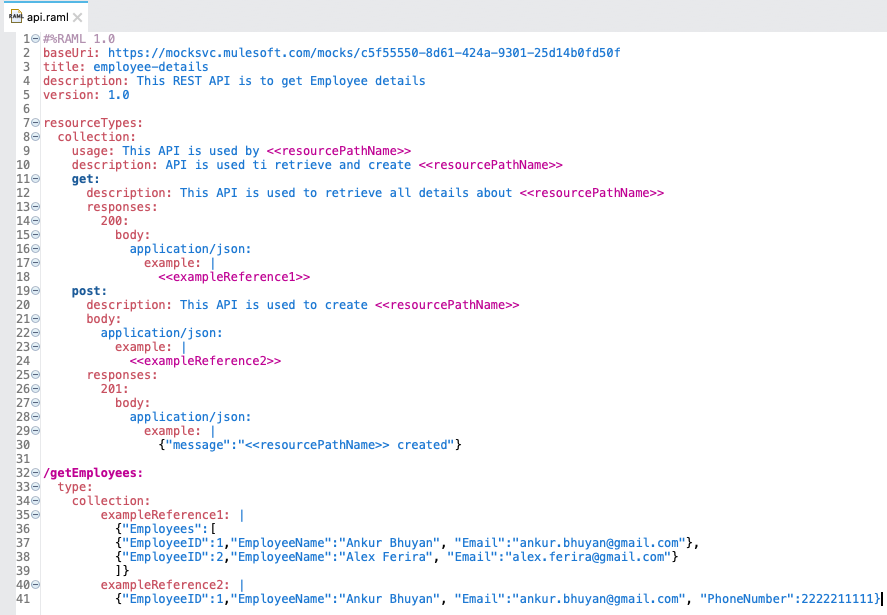
- 22. Difference between ResourceTypes and Traits?
-
What Is ResourceTypes?
- ResourceTypes is like resource in that it can specify the descriptions, methods, and its parameters. Resource that uses resourceTypes can inherit its nodes. ResourceTypes can use and inherit from other resourceTypes.
- In order to implement the patterns found in the API, resource types use reserved and user-defined parameters surrounded by double angle brackets (<< and >>).
-
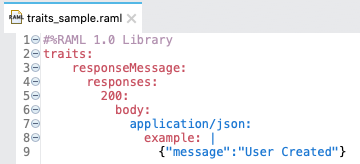
What Is Traits?
- Traits is like function and is used to define common attributes for HTTP method (GET, PUT, POST, PATCH, DELETE, etc) such as whether or not they are filterable, searchable, or pageable.
- Whereas a resource type is used to extract patterns from resource definitions, a trait is used to extract patterns from method definitions that are common across resources.
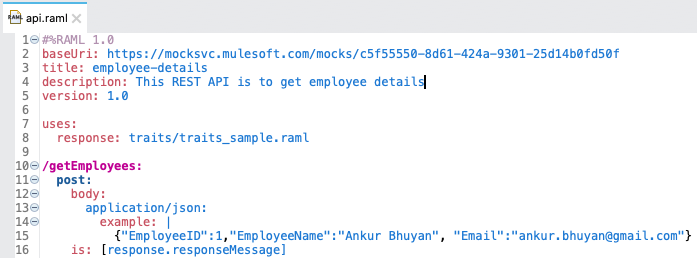
- 23. Difference between map and mapObject?
- "map" operator is used for Arrays, "mapObject" is used for Objects.
- We can't use "mapObject" operator for Arrays, similarly we can't use "map" operator for objects.
-
map
- It transforms every item in an Array and returns an Array.
- map takes two parameters an Array and a lambda.
- map takes two parameters an Array and a lambda.
-
Syntax :
map(Array<T>, ((T, Number) -> R)): Array<R> - T represents the type of items that the input Array contains.
- R represents the type of items that output Array returns.
- Number represents the index of the input Array.
-
mapObject
- It transforms an Object to a new Object.
- mapObject is used when we want to change the keys and/or values on an Object to be something else.
-
Syntax 1 : mapObject(Object
- "mapObject" takes two parameter an "Object" and a "lambda".
-
Syntax 2 : mapObject Object
- "Object" takes two parametes a value and key, and returns a new Object
-
Syntax 3 : mapObject (V,K,Number) -> Object
- "lambda" takes three parametes a value, key and index, and returns a new Object.
- 24. What is C4E and how it works? Difference between C4E and COE?
- A Center for Enablement (C4E) is a cross-functional team tasked with productizing, publishing, and harvesting reusable assets and best practices.
- Principles behind a C4E
- C4E is a group that drives the IT operating model shift.
- A C4E is in charge of enabling business divisions, including IT, to build and drive the consumption of assets successfully, enabling speed and agility.
- The C4E is a cross-functional team typically staffed with members from central IT, line-of-business (LoB) departments, and digital innovation teams who are charged with productizing, publishing, and harvesting reusable assets and best practices.
- The primary goals of the C4E are to run the API platform and enable teams on how to best use it while developing reusable APIs to accelerate innovation and deliver change more efficiently.
-
Center of Excellence (COE):
- A hybrid of “platform team” and “stream aligned team” which can sometimes struggle with scaled demand from consuming lines of business.
-
Center for Enablement (C4E):
- A C4E team is a hybrid between a “Platform Team” and an “Enablement Team” that is explicitly designed to support scale and governance by enabling external Stream Aligned Teams with standards and reusable tools/components.
- Difference between COE and C4E
-
Mindset
- CoE : Governance.
- C4E : Production and consumption.
-
Delivery Model
- CoE : Project focused. centralized within IT or defined by central IT.
- C4E : It builds capability to enable the LoBs (line of business) to deliver projects independently.
-
Governance and Access
- CoE : Strict and rigit, limited access to IT systems.
- C4E : Governed through APIs, self-service access.
-
Assets
- CoE : EA patterns, domain architecture, best practices, security and access contol models.
- C4E : API, domain architectures, templates and project accelerators, best practices.
-
Consumer of Assets
- CoE : Cetral IT, SIs.
- C4E : It, Sis, LoB IT, App Dev, Creative, ISVs.
-
Consumtion model
- CoE : Cenralized, request-based.
- C4E : Developer portals, data marketplaces, SDKs, embedded tools.
-
Ownership
- CoE : Central IT owns the infrastructure, applications and data.
- C4E : Central IT are stewards of platform, access is self-serve.
-
Enablement
- CoE : Complex, document-driven.
- C4E : Evangelism, community-building, self-place trining.
-
Domain expertise
- CoE : Centralized.
- C4E : Decentralized or Federated.
-
Mindset
- 25. What read($, "application/json") does?
- Reads a string or binary and returns parsed content.
- This function can be useful if the reader cannot determine the content type by default.
- 26. What is vCore and Worker?
-
vCore
- A unit of compute capacity for processing on CloudHub, which is equal to one virtual core. In simple words, vCore is used to compute how many applications we can run on worker.
- Up to 10 Mule Applications (0.1 vCore) can be deployed for every 1 VCore purchased.
-
worker
- Workers are dedicated instances of Mule runtime engine that run our integration applications on CloudHub.
- Worker is an dedicated Instance of Mule hosted on AWS is used to run our integration application.
- Features of Workers
- Capacity : Each worker has a specific amount of capacity to process data. Select the size of your workers when configuring an application.
- Isolation : Each worker runs in a separate container from every other application.
- Manageability : Each worker is deployed and monitored independently.
- Locality : Each worker runs in a specific worker cloud, such as the US, EU, or Asia-Pacific.
- Workers Table
- Worker sizes have different compute, memory, and storage capacities.
- We can scale workers "vertically" by selecting one of the available worker sizes.
Worker Size Worker Memory Heap Memory Disk Storage Size 0.1 vCores 1 GB 500 MB 8 GB 0.2 vCores 2 GB 1 GB 8 GB 1 vCore 4 GB 2 GB 12 GB 2 vCores 8 GB 4 GB 40 GB 4 vCores 16 GB 8 GB 88 GB 8 vCores 32 GB 16 GB 168 GB 16 vCores 64 GB 32 GB 328 GB
- 27. What is scalability? What is the difference between Vertical and Horizontal Scaling?
-
Scalability
- Scalability is the measure of a system’s ability to increase or decrease in performance and cost in response to changes in application and system processing demands.
- A system that scales well will be able to maintain or increase its level of performance even as it is tested by larger and larger operational demands.
-
Horizontal Scaling:
- When new server racks are added to the existing system to meet the higher expectation, it is known as horizontal scaling.
- Horizontal Scaling, often called “scaling out,” involves adding more machines to your existing pool of resources. This strategy is akin to adding more lanes to a highway to accommodate increased traffic.
-
Vertical Scaling:
- When new resources are added to the existing system to meet the expectation, it is known as vertical scaling.
- Vertical Scaling, or “scaling up,” is about enhancing the capabilities of an existing machine, such as increasing its CPU power, memory, or storage. This is similar to upgrading a car’s engine for better speed and performance.
- Differences between Horizontal and Vertical Scaling are as follows:
Horizontal scaling Vertical scaling When new server racks are added to the existing system to meet the higher expectation, it is known as horizontal scaling. When new resources are added in the existing system to meet the expectation, it is known as vertical scaling It expands the size of the existing system horizontally. It expands the size of the existing system vertically. It is easier to upgrade. It is harder to upgrade and may involve downtime. It is difficult to implement It is easy to implement It is costlier, as new server racks comprise a lot of resources It is cheaper as we need to just add new resources It takes more time to be done It takes less time to be done High resilience and fault tolerance Single point of failure Examples of databases that can be easily scaled- Cassandra, MongoDB, Google Cloud Spanner Examples of databases that can be easily scaled- MySQL, Amazon RDS - Horizontal Vs. Vertical Scaling: At a Glance
Horizontal scaling Vertical scaling Description Increase or decrease the number of nodes in a cluster or system to handle an increase or decrease in workload Increase or decrease the power of a system to handle increased or reduced workload Example Add or reduce the number of virtual machines (VM) in a cluster of VMs Add or reduce the CPU or memory capacity of the existing VM Execution Scale in/out Scale up/down Workload distribution Workload is distributed across multiple nodes.Parts of the workload reside on these different nodes A single node handles the entire workload. Concurrency Distributes multiple jobs across multiple machines over the network, at a go. This reduces the workload on each machine Relies on multi-threading on the existing machine to handle multiple requests at the same time Required architecture Distributed Any Implementation Takes more time, expertise, and effort Takes less time, expertise, and effort Complexity and maintenance Higher lower Configuration This requires modifying a sequential piece of logic in order to run workloads concurrently on multiple machines No need to change the logic. The same code can run on a higher-spec device Downtime No Yes Load balancing Necessary to actively distribute workload across the multiple nodes Not required in the single node Failure resilience Low because other machines in the cluster offer backup High since it’s a single source of failure Costs High costs initially; optimal over time Low-cost initially; less cost-effective over time Networking Quick inter-machine communication Slower machine-to-machine communication Performance Higher Lower Limitation Add as many machines as you can Limited to the resource capacity the single machine can handle
- 28. What are the data types used in raml?
-
The RAML type system defines the following built-in types:
- any
- object
- array
- union via type expression
- Following scalar types: number, boolean, string, date-only, time-only, datetime-only, datetime, file, integer, nil
- Object
#%RAML 1.0 title: Employee Types types: Employee: type: object properties: name: required: true type: string - Array
#%RAML 1.0 title: Email Types types: Email: type: object properties: name: type: string Emails: type: array items: Email minItems: 1 uniqueItems: true - Union Type
A union type MAY be used to allow instances of data to be described by any of several types. A union type MUST be declared via a type expression that combines 2 or more types delimited by pipe (|) symbols; these combined types are referred to as the union type's super types.
#%RAML 1.0 title: Phone and Notebook Types types: Phone: type: object properties: manufacturer: type: string numberOfSIMCards: type: number kind: string Notebook: type: object properties: manufacturer: type: string numberOfUSBPorts: type: number kind: string Device: type: Phone | Notebook#%RAML 1.0 title: Cat and Dog Types types: CatOrDog: type: Cat | Dog # elements: Cat or Dog Cat: type: object properties: name: string color: string Dog: type: object properties: name: string fangs: string - Scaller Type
- String
#%RAML 1.0 types: EmailAddress: type: string pattern: ^.+@.+\..+$ minLength: 3 maxLength: 320 - Number
#%RAML 1.0 types: Weight: type: number minimum: -1.1 maximum: 20.9 format: float multipleOf: 1.1 - Integer
Any JSON number that is a positive or negative multiple of 1. The integer type inherits its facets from the number type.
#%RAML 1.0 types: Age: type: integer minimum: -3 maximum: 5 format: int8 - Boolean
#%RAML 1.0 types: IsMarried: type: boolean - Date
#%RAML 1.0 types: birthday: type: date-only # no implications about time or offset example: 2015-05-23 lunchtime: type: time-only # no implications about date or offset example: 12:30:00 fireworks: type: datetime-only # no implications about offset example: 2015-07-04T21:00:00 created: type: datetime example: 2016-02-28T16:41:41.090Z format: rfc3339 # the default, so no need to specify If-Modified-Since: type: datetime example: Sun, 28 Feb 2016 16:41:41 GMT format: rfc2616 # this time it's required, otherwise, the example format is invalid - File
The file type can constrain the content to send through forms. When this type is used in the context of web forms it SHOULD be represented as a valid file upload in JSON format. File content SHOULD be a base64-encoded string.
#%RAML 1.0 types: userPicture: type: file fileTypes: ['image/jpeg', 'image/png'] maxLength: 307200 customFile: type: file fileTypes: ['*/*'] # any file type allowed maxLength: 1048576 - Nil
In RAML, the type nil is a scalar type that SHALL allow only nil data values. Specifically, in YAML, it allows only YAML's null (or its equivalent representations, such as ~). In JSON, it allows only JSON's null, and in XML, it allows only XML's xsi:nil.The following example shows the assignment of the nil type to comment:
#%RAML 1.0 types: NilValue: type: object properties: name: comment: nil example: name: Fred comment: # Providing a value here is not allowed.The following example shows how to represent nilable properties using a union:#%RAML 1.0 types: NilValue: type: object properties: name: comment: nil | string # equivalent to -> # comment: string? example: name: Fred comment: # Providing a value or not providing a value here is allowed.
- String
Comments