- Mule 4 container Configuration
The thread pool is automatically configured by Mule at startup, applying formulas that consider available resources such as CPU and memory.
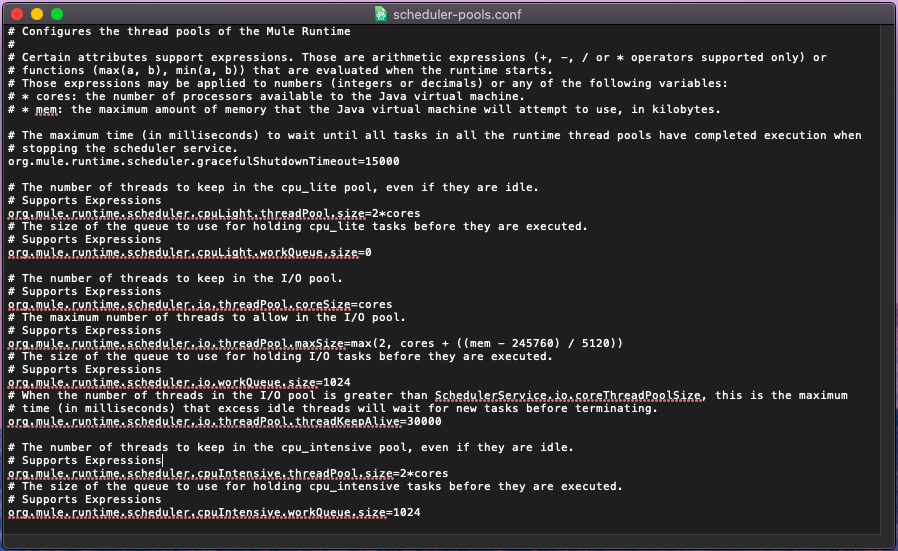
We can modify these global formulas by editing the MULE_HOME/conf/schedulers-pools.conf file in our local Mule instance.
In Mule we have TWO Scheduling Strategy
- UBER :- Unified scheduling strategy. (Default)
- DEDICATED :- Separated pools strategy. (Legacy)
- UBER Scheduling Strategy
- org.mule.runtime.scheduler.uber.threadPool.coreSize=cores
- org.mule.runtime.scheduler.uber.threadPool.maxSize=max(2, cores + mem - 245760) / 5120
- org.mule.runtime.scheduler.uber.workQueue.size=0
- org.mule.runtime.scheduler.uber.threadPool.threadKeepAlive=30000
- DEDICATED Scheduling Strategy
- org.mule.runtime.scheduler.cpuLight.threadPool.size=2*cores
- org.mule.runtime.scheduler.cpuLight.workQueue.size=0
- org.mule.runtime.scheduler.io.threadPool.coreSize=cores
- org.mule.runtime.scheduler.io.threadPool.maxSize=max(2, cores + mem - 245760) / 5120
- org.mule.runtime.scheduler.io.workQueue.size=0
- org.mule.runtime.scheduler.io.threadPool.threadKeepAlive=30000
- org.mule.runtime.scheduler.cpuIntensive.threadPool.size=2*cores
- org.mule.runtime.scheduler.cpuIntensive.workQueue.size=2*cores
When the strategy is set to UBER, the following configuration applies:
When the strategy is set to DEDICATED, the parameters from the default UBER strategy are ignored.
To enable this configuration, uncomment the following parameters in our schedulers-pools.conf file:
Example schedulers-pools.conf file:
Comments